Zero-Shot Action Recognition
Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks
Large datasets are often used to improve the accuracy of action recognition. However, very large datasets are problematic as, for example, the annotation of large datasets is labor-intensive. This has encouraged research in zero-shot action recognition (ZSAR). Presently, most ZSAR methods recognize actions according to each video frame. These methods are affected by light, camera angle, and background, and most methods are unable to process time series data. The accuracy of the model is reduced owing to these reasons. In this paper, in order to solve these problems, we propose a three-stream graph convolutional network that processes both types of data. Our model has two parts. One part can process RGB data, which contains extensive useful information. The other part can process skeleton data, which is not affected by light and background. By combining these two outputs with a weighted sum, our model predicts the final results for ZSAR. Experiments conducted on three datasets demonstrate that our model has greater accuracy than a baseline model. Moreover, we also prove that our model can learn from human experience, which can make the model more accurate.
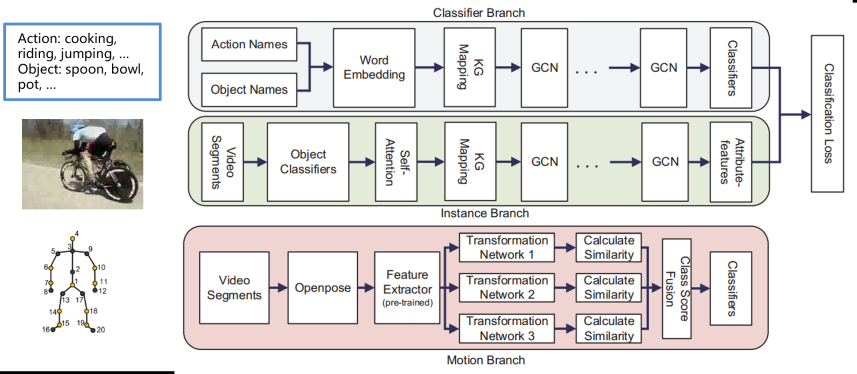
Wu, Nan; Kawamoto, Kazuhiko. 2021. "Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks" Sensors 21, no. 11: 3793 [paper].
Improving zero-shot action recognition using human instruction with text description
Zero-shot action recognition, which recognizes actions in videos without having received any training examples, is gaining wide attention considering it can save labor costs and training time. Nevertheless, the performance of zero-shot learning is still unsatisfactory, which limits its practical application. To solve this problem, this study proposes a framework to improve zero-shot action recognition using human instructions with text descriptions. The proposed framework manually describes video contents, which incurs some labor costs; in many situations, the labor costs are worth it. We manually annotate text features for each action, which can be a word, phrase, or sentence. Then by computing the matching degrees between the video and all text features, we can predict the class of the video. Furthermore, the proposed model can also be combined with other models to improve its accuracy. In addition, our model can be continuously optimized to improve the accuracy by repeating human instructions. The results with UCF101 and HMDB51 showed that our model achieved the best accuracy and improved the accuracies of other models.
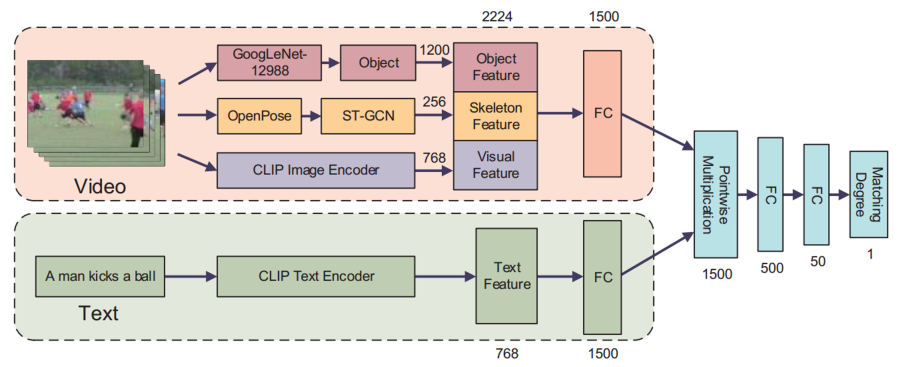
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Improving zero-shot action recognition using human instruction with text description, Applied Intelligence, vol.53, pp.24142–24156, 2023 [paper][SharedIt][arXix].
Zero-Shot Action Recognition with ChatGPT-Based Instruction
As deep learning continues to evolve, datasets are becoming increasingly larger, leading to higher costs for manual labeling. Zero-shot learning eliminates the need for substantial labor costs to label training datasets. It even allows the model to predict new classes with slight modifications. However, the accuracy of zero-shot learning still remains relatively low and makes practical applications challenging. Some recent research has tried to improve accuracy by manually annotating features, but this approach again requires labor-intensive input. To reduce these labor costs, we employ ChatGPT, which can generate features automatically without any manual involvement. Importantly, this approach maintains high accuracy levels, surpassing other automated methods.
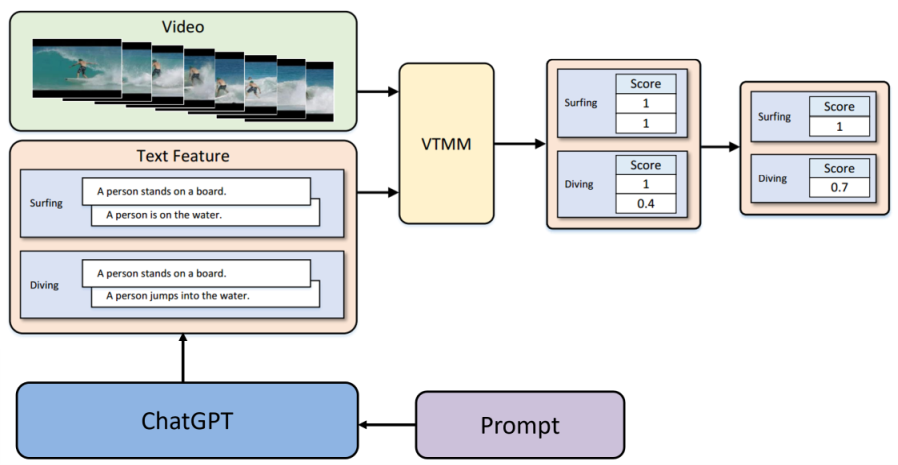
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Zero-Shot Action Recognition with ChatGPT-based Instruction, Advanced Computational Intelligence and Intelligent Informatics, Communications in Computer and Information Science, vol. 1932, pp.18-28, 2024 [paper].