Generative AI
Video Disentanglement
In this paper, we propose a sequential variational autoencoder for video disentanglement, which is a representation learning method that can be used to separately extract static and dynamic features from videos. Building sequential variational autoencoders with a two-stream architecture induces inductive bias for video disentanglement. However, our preliminary experiment demonstrated that the two-stream architecture is insufficient for video disentanglement because static features frequently contain dynamic features. Additionally, we found that dynamic features are not discriminative in the latent space. To address these problems, we introduced an adversarial classifier using supervised learning into the two-stream architecture. The strong inductive bias through supervision separates dynamic features from static features and yields discriminative representations of the dynamic features. Through a comparison with other sequential variational autoencoders, we qualitatively and quantitatively demonstrate the effectiveness of the proposed method on the Sprites and MUG datasets.
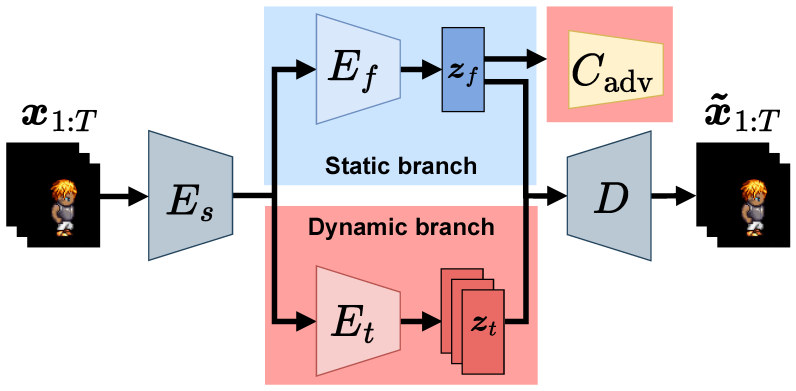
Haga, Takeshi, Hiroshi Kera, and Kazuhiko Kawamoto, Sequential Variational Autoencoder with Adversarial Classifier for Video Disentanglement, Sensors 23, no. 5: 2515, 2023 [paper].
Image Animation with Flow Style Transfer
We propose a method for animating static images using a generative adversarial network (GAN). Given a source image depicting a cloud image and a driving video sequence depicting a moving cloud image, our framework generates a video in which the source image is animated according to the driving sequence. By inputting the source image and optical flow of the driving video into the generator, a video is generated that is conditioned by the optical flow. The optical flow enables the application of the captured motion of clouds in the source image. Further, we experimentally show that the proposed method is more effective than the existing methods for animating a keypoint-less video (in which the keypoints cannot be explicitly determined) such as a moving cloud image. Furthermore, we show an improvement in the quality of the generated video due to the use of optical flow in the video reconstruction.
![]()
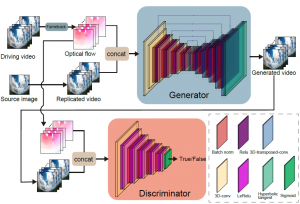
Kazuma Kurisaki and Kazuhiko Kawamoto, Animating Cloud Images With Flow Style Transfer, IEEE Access, Vol.9, pp.3269-3277, 2021 [paper][GitHub].
Audio-Visual Model for Generating Eating Sounds Using Food ASMR Videos
We present an audio-visual model for generating food texture sounds from silent eating videos. We designed a deep network-based model that takes the visual features of the detected faces as input and outputs a magnitude spectrogram that aligns with the visual streams. Generating raw waveform samples directly from a given input visual stream is challenging; in this study, we used the Griffin-Lim algorithm for phase recovery from the predicted magnitude to generate raw waveform samples using inverse short-time Fourier transform. Additionally, we produced waveforms from these magnitude spectrograms using an example-based synthesis procedure. To train the model, we created a dataset containing several food autonomous sensory meridian response videos. We evaluated our model on this dataset and found that the predicted sound features exhibit appropriate temporal synchronization with the visual inputs. Our subjective evaluation experiments demonstrated that the predicted sounds are considerably realistic to fool participants in a “real” or “fake” psychophysical experiment.
Kodai Uchiyama and Kazuhiko Kawamoto, Audio-Visual Model for Generating Eating Sounds Using Food ASMR Videos, IEEE Access, Vol.9, pp.50106-50111, 2021 [paper][GitHub].
Compositional Zero-Shot Video Generation by Deep Learning
We propose a conditional generative adversarial network (GAN) model for zero-shot video generation. In this study, we have explored zero-shot conditional generation setting. In other words, we generate unseen videos from training samples with missing classes. The task is an extension of conditional data generation. The key idea is to learn disentangled representations in the latent space of a GAN. To realize this objective, we base our model on the motion and content decomposed GAN and conditional GAN for image generation. We build the model to find better-disentangled representations and to generate good-quality videos. We demonstrate the effectiveness of our proposed model through experiments on the Weizmann action database and the MUG facial expression database.
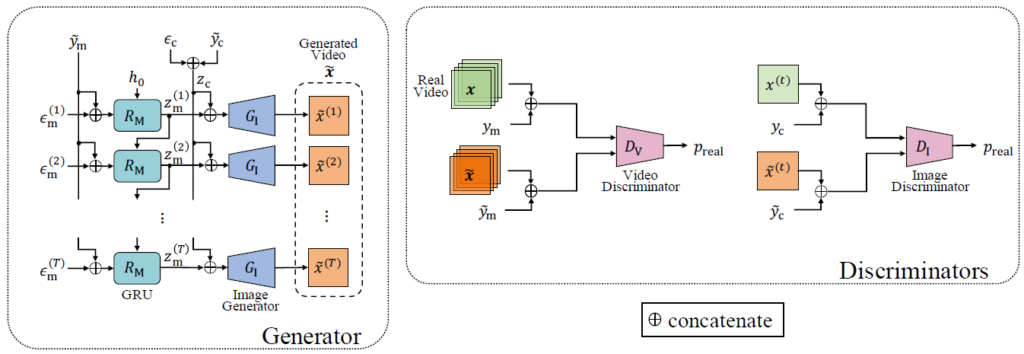

Shun Kimura and Kazuhiko Kawamoto, "Conditional Motion and Content Decomposed GAN for Zero-Short Video Generation," In Proc. of the 7th International Workshop on Advanced Computational Intelligence and Intelligent Informatics, 2021 [arXix].
Depth-conditional GANs for Video Generation
In the past few years, several generative adversarial networks (GANs) for video generation have been proposed although most of them only use color videos to train the generative model. However, to make the model understand scene dynamics more accurately, not only optical information but also three-dimensional geometrical information is important. In this paper, using depth video together with color video, we propose a GAN architecture for video generation. In the generator of our architecture, the depth video is generated in the first half and in the second half, the color video is generated by solving the domain translation from the depth to the color. By modeling the scene dynamics with a focus on the depth information, we were able to produce videos of higher quality than the conventional method. Furthermore, we show that our method produces better video samples than ones by conventional method in terms of both variety and quality when evaluating on facial expression and hand gesture datasets.
Y. Nakahira and K. Kawamoto, DCVGAN: Depth Conditional Video Generation, IEEE International Conference on Image Processing (ICIP), pp. 749-753, 2019 [paper][GitHub].
Y. Nakahira and K. Kawamoto, Generative adversarial networks for generating RGB-D videos, Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1276-1281, 2018 [paper].