一人称行動認識
ドメイン適応を用いた一人称行動認識
様々な環境下で一人称行動認識の正解率を向上させるために,ドメイン適応を用いた一人称行動認識を提案する.提案手法は,2 ストリーム型の一人称行動認識モデルでドメイン識別器の敵対的な学習を行うことで,教師無しドメイン適応を実現する.EPIC-KITCHENS データセット内のキッチンとユーザが異なる動画において,ドメイン適応により正解率が6%以上向上した.
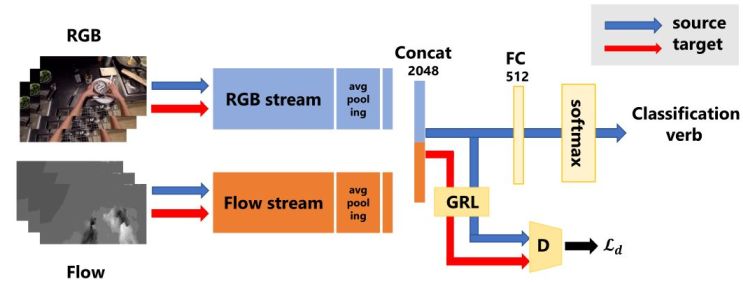
木内拓実, 計良宥志, 川本一彦,ドメイン適応を用いた一人称行動認識,I21-36,第24回画像の認識・理解シンポジウム,2021.
インタラクション領域検出
我々は、一人称視点のビデオにおける物体と行動の相互作用領域を検出するためのディープモデルを提案します。このタスクは、物体検出と行動認識を同時に含み、行動に関与する物体のみを検出する必要があります。我々は、ビデオクリップの1フレームのみに注釈を付けることで学習を可能にする、2ストリームのディープアーキテクチャを設計しました。これにより、ビデオクリップのすべてのフレームにバウンディングボックスと物体クラスを割り当てるという時間のかかる注釈付けを避けることができます。本論文では、マルチタスク学習のための2ストリームアーキテクチャの出力層の4つの可能な構造の比較評価の結果を報告します。EPICKITCHENSデータセットでの実験結果は、物体検出と行動認識を融合する構造が他の構造よりも優れたパフォーマンスを提供することを示しています。
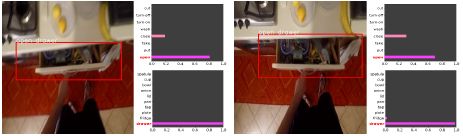
Shinobu Takahashi and Kazuhiko Kawamoto, Object-Action Interaction Region Detection in Egocentric Videos, In Proc. of the 9th International Symposium on Computational Intelligence and Industrial Applications, 2020.
マルチタスクアーキテクチャによる一人称行動認識
本研究では,一人称映像から行動推定を行うための深層学習モデルアーキテクチャを提案する.一人称行動認識では深層学習モデルを十分に学習するためのデータセットを収集することは一般に困難であることから,複数のタスクを同時に解くマルチタスク学習を導入する.画像特徴とオプティカルフロー特徴を抽出する2種類のCNNを導入し,特徴マップでの深層特徴量を融合させながら,スキップ構造を導入することでそれぞれのCNNがタスクに対して有効に働くようにネットワークを構築する.実動画を用いた一人称行動認識実験では,提案するアーキテクチャを利用することで,先行研究と比較して認識精度が向上することを示す.
中村伊吹,川本一彦,岡本一志,一人称行動認識のための深層マルチタスクアーキテクチャ,電子情報通信学会論文誌D, Vol.J102-D, No.8, pp.506-513, 2019 [paper].
Shunpei Kobayashi and Kazuhiko Kawamoto, First-Person Activity Recognition by Deep Multi-task Network with Hand Segmentation, In Proc. of ISCIIA&ITCA, 2018.
画像合成による深層学習
我々は、ディープラーニングを用いた第一人者視点の読書活動認識のためのビジョンベースの方法を提案します。ディープラーニングの成功には、大量のトレーニングデータが重要な役割を果たすことがよく知られています。画像分類とは異なり、読書活動認識のための公開データセットは少なく、本の画像の収集は著作権の問題を引き起こす可能性があります。本論文では、肯定的なトレーニング画像を生成するための合成アプローチを開発します。我々のアプローチは、コンピュータ生成画像と実際の背景画像を合成します。実験では、この合成が事前訓練されたディープ畳み込みニューラルネットワークと組み合わせることで効果的であり、また我々の訓練されたニューラルネットワークが他のベースラインよりも優れていることを示します。

Yuta Segawa, Kazuhiko Kawamoto, and Kazushi Okamoto, First-person reading activity recognition by deep learning with synthetically generated images, EURASIP Journal on Image and Video Processing, vol.2018-33, 13 pages, 2018 [paper].